> ## Documentation Index
> Fetch the complete documentation index at: https://docs.reworkd.ai/llms.txt
> Use this file to discover all available pages before exploring further.
# Introduction
> Reworkd - Extract web data at scale
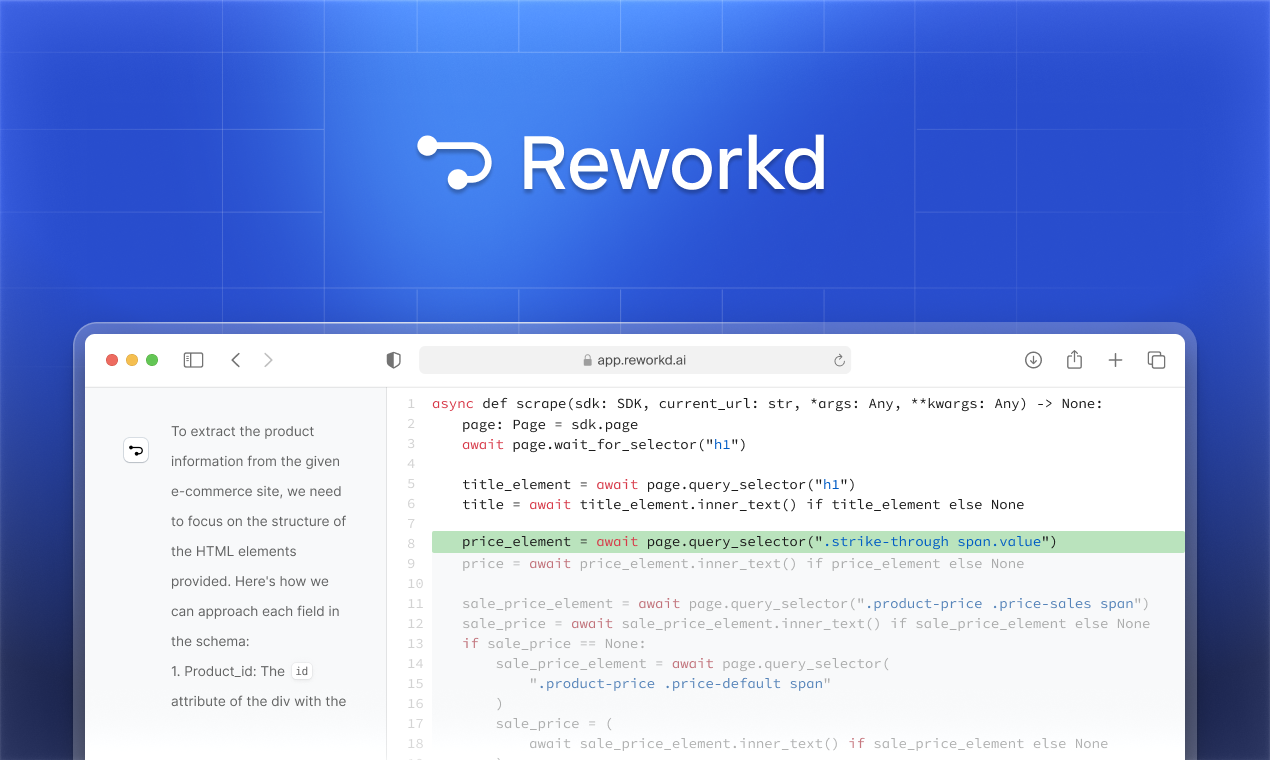 Reworkd uses LLMs to parse, understand, and interact with web pages to help users scrape web data at ***scale***.
Reworkd customers are extracting millions of rows of data to help build data constrained products, fine tune domain specific language models, and enrich existing data pipelines.
We also built AgentGPT! If you're looking for info on AgentGPT, please visit our
[Github](https://github.com/reworkd/AgentGPT)
Learn how to scrape a website and its sub pages with Reworkd
Understand all of the key terms required to get started
Learn how to export the data you scrape
Read the latest updates on the Reworkd blog
Reworkd uses LLMs to parse, understand, and interact with web pages to help users scrape web data at ***scale***.
Reworkd customers are extracting millions of rows of data to help build data constrained products, fine tune domain specific language models, and enrich existing data pipelines.
We also built AgentGPT! If you're looking for info on AgentGPT, please visit our
[Github](https://github.com/reworkd/AgentGPT)
Learn how to scrape a website and its sub pages with Reworkd
Understand all of the key terms required to get started
Learn how to export the data you scrape
Read the latest updates on the Reworkd blog